Deep Generative Models
- Representation learning with variational autoencoders
- Enforcing distributional accuracy in generative adversarial networks
Representation learning with variational autoencoders
Is it possible to learn a powerful generative model that matches the true data distribution with useful data representations amenable to downstream tasks in an unsupervised way? —This question is the driving force behind most unsupervised representation learning via the state-of-the-art deep generative modeling methods.
Unsupervised representation learning via generative modeling is a staple to many computer vision applications in the absence of labeled data. Variational Autoencoders (VAEs) are powerful generative models that learn representations useful for data generation. However, due to inherent challenges in the training objective, VAEs fail to learn useful representations amenable for downstream tasks. Regularization-based methods that attempt to improve the representation learning aspect of VAEs come at a price: poor sample generation. In this work, we explore this representation-generation trade-off %between representation learning and sample generation in detail for regularized VAEs and introduce a new family of VAE latent priors, namely decoupled priors, or dpVAEs, that decouple the representation space from the generation space. This decoupling enables the direct use of VAE regularizers on the representation space without impacting the distribution used for sample generation, and thereby reaping the representation learning benefits of the regularizations without sacrificing the sample generation. dpVAE leverages invertible networks to learn a bijective mapping from an arbitrarily complex representation distribution to a simple, tractable, generative distribution. Decoupled priors can be adapted to the state-of-the-art VAE regularizers without additional hyperparameter tuning. Experiments with diffferent regularizers on MNIST, SVHN, and CelebA demonstrate, quantitatively and qualitatively, that dpVAE fixes sample generation for regularized VAEs.
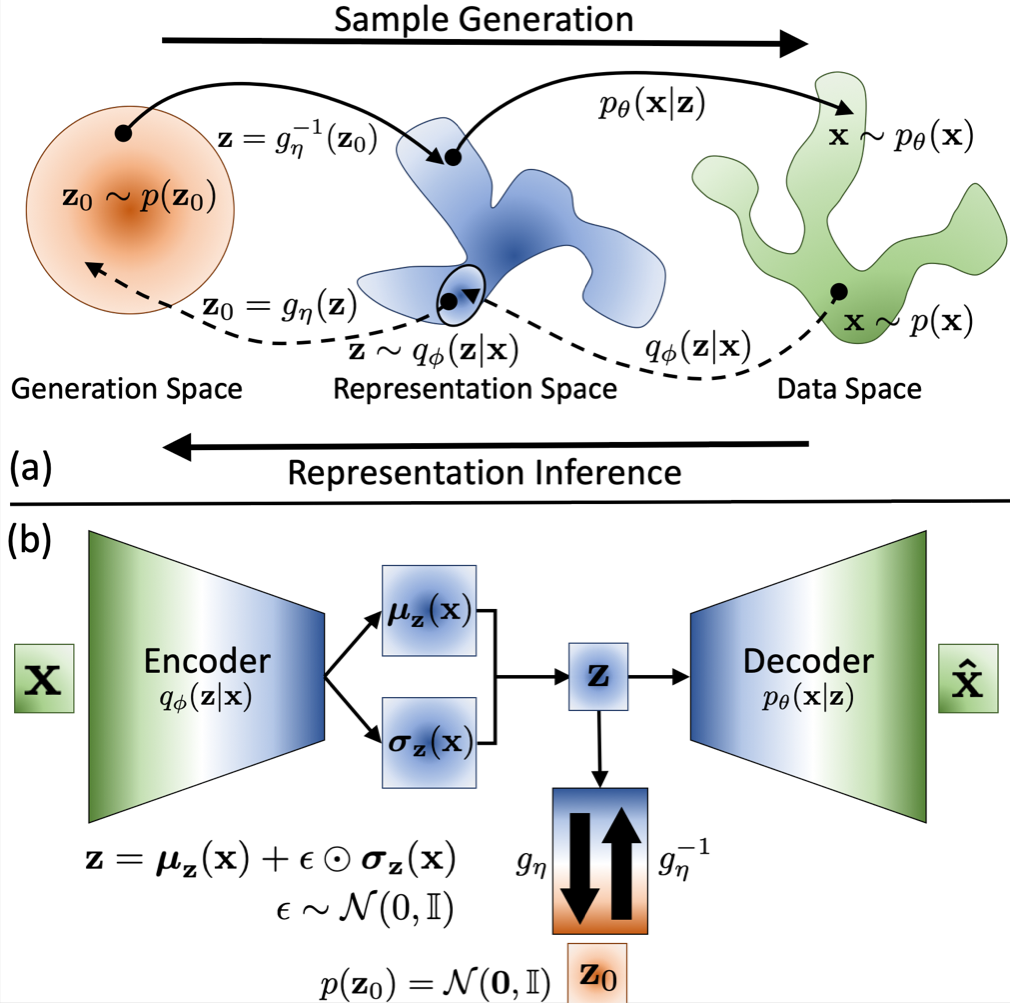
dpVAE: (a) The latent space is decoupled into a generation space with a simple, tractable distribution (e.g. standard normal) and a representation space whose distribution can be arbitrarily complex and is learned via a bijective mapping to the gen- eration space. (b) Architecture of a VAE with the decoupled prior. The g−bijection is jointly trained with the VAE generative (i.e. decoder) and inference (i.e. encoder) models.
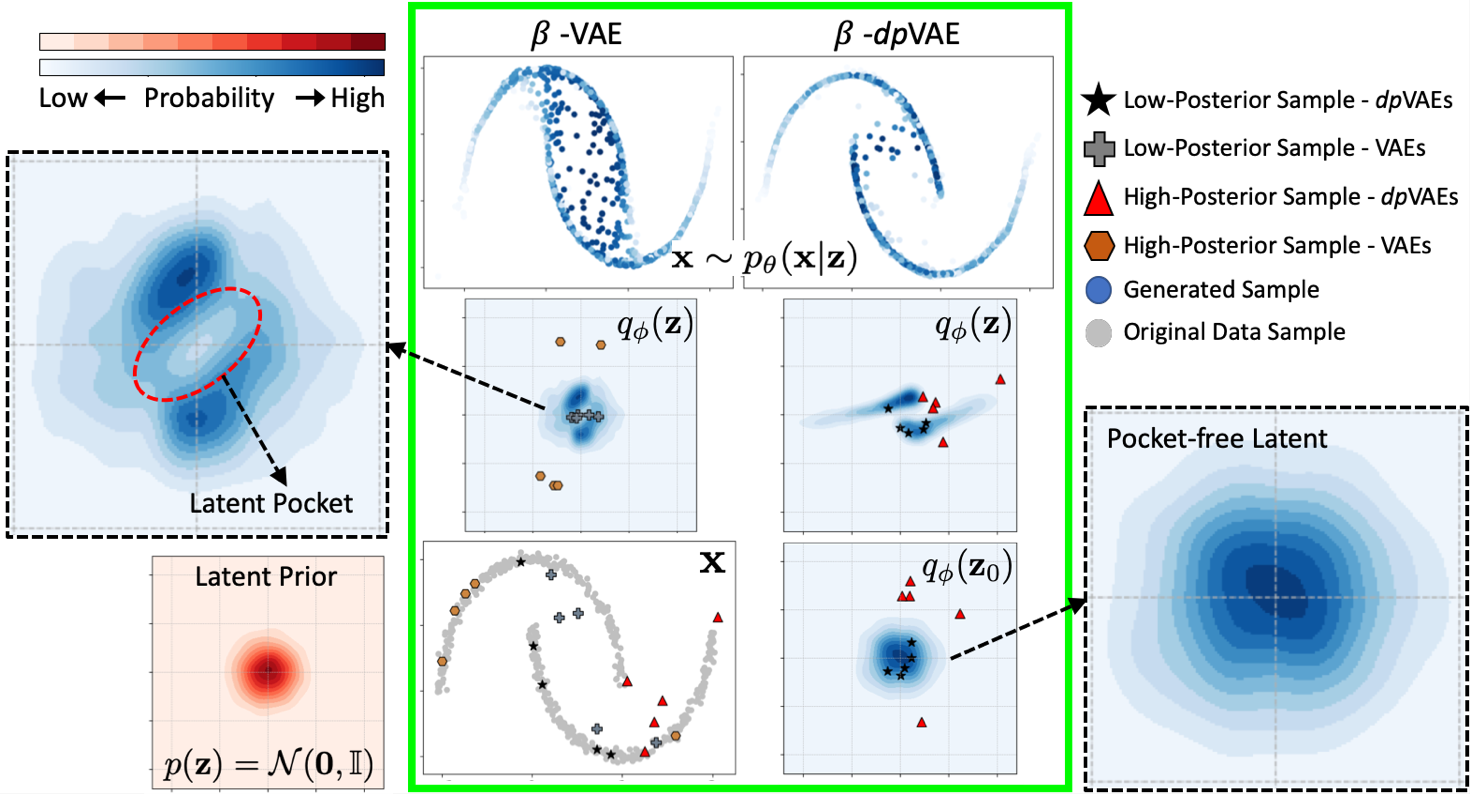
dpVAE fixes sample generation for a regularized VAE. The green box shows β-VAE (left column) and β-VAE with the proposed decoupled prior (right column), each trained on the two moons dataset. β-VAE: Top to bottom shows the gener- ated samples (colors reflect probability of generation), the aggregate posterior qφ(z) and the training samples. The low-posterior samples lie in the latent pockets of qφ(z) (shown in enlarged section on the left) and correspond to off-manifold samples in the data space, and high-posterior samples correspond to latent leaks. The β-dpVAE decouples the representation z and generation z0 spaces. The generation space is pocket-free and very close to standard normal, resulting in generating samples on the data manifold. Furthermore, the representation learning is well established in the representation space.
Related publications:
Riddhish Bhalodia, Iain Lee, Shireen Y. Elhabian. dpVAEs: Fixing Sample Generation for Regularized VAEs. arXiv:1911.10506, 2019.
Enforcing distributional accuracy in generative adversarial networks
Joint work with: Ross Whitaker
In this work, we address the ability of generative adversarial networks (GANs) to model complex distributions of data in high-dimensional spaces. Our proposition is that the more effective the adversary is in discriminating the output of the generator, the more effective the generator will be at modeling (or generating) the distribution represented by the training data. The most extreme failure of GANs in this context is mode collapse, and there are several pro- posed methods to address that problem. However, mode collapse is merely a symptom of a more general problem of GANs, where the generator fools the adversary while failing to faithfully model the distribution of the training data. Here, we address the challenge of constructing and evaluating GANs that more effectively represent the input distribution. We introduce an adversarial architecture that processes sets of generated and real samples, and discriminates between the origins of these sets (i.e., training versus generated data) in a flexible, permutation invariant man- ner. We present quantitative and qualitative results that demonstrate the effectiveness of this approach relative to state-of-the-art methods for avoiding mode collapse.
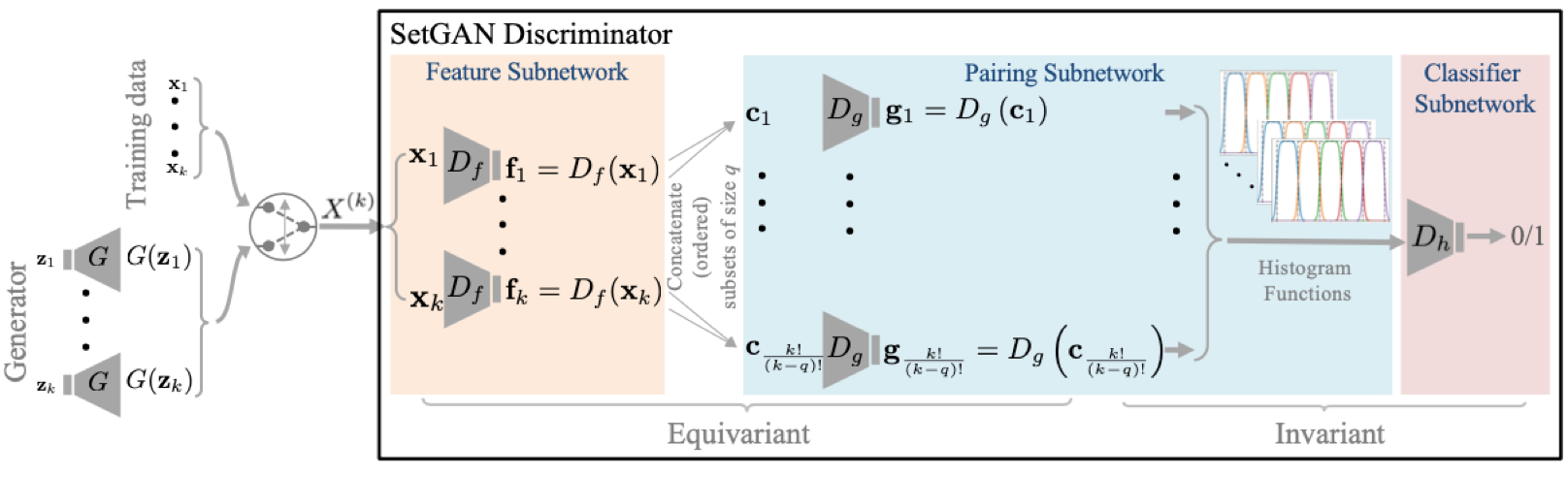
SetGAN architecture

2D grid experiment

Generated data for CelebA. SetGAN5 produces sharp images with high variety.
Related publications:
Alessandro Ferrero, Shireen Y. Elhabian, Ross Whitaker. SetGANs: Enforcing Distributional Accuracy in Generative Adversarial Networks. arXiv:1907.00109, 2019.
Copyright © 2022 Shireen Y. Elhabian. All rights reserved.