SCIENTIFIC COMPUTING AND IMAGING INSTITUTEat the University of Utah
An internationally recognized leader in visualization, scientific computing, and image analysis
SCI Publications
2012
The Four-Level Nested Model Revisited: Blocks and Guidelines
M.D. Meyer, M. Sedlmair, T. Munzner.
“The Four-Level Nested Model Revisited: Blocks and Guidelines,” In Workshop on BEyond time and errors: novel evaLuation methods for Information Visualization (BELIV), IEEE VisWeek 2012, 2012.
ABSTRACT
×
We propose an extension to the four-level nested model for design and validation of visualization systems that defines the term \"guidelines\" in terms of blocks at each level. Blocks are the outcomes of the design process at a specific level, and guidelines discuss relationships between these blocks. Within-level guidelines provide comparisons for blocks within the same level, while between-level guidelines provide mappings between adjacent levels of design. These guidelines help a designer choose which abstractions, techniques, and algorithms are reasonable to combine when building a visualization system. This definition of guideline allows analysis of how the validation efforts in different kinds of papers typically lead to different kinds of guidelines. Analysis through the lens of blocks and guidelines also led us to identify four major needs: a definition of the meaning of block at the problem level; mid-level task taxonomies to fill in the blocks at the abstraction level; refinement of the model itself at the abstraction level; and a more complete set of guidelines that map up from the algorithm level to the technique level. These gaps in visualization knowledge present rich opportunities for future work.
Sasaki Metrics for Analysis of Longitudinal Data on Manifolds
P. Muralidharan, P.T. Fletcher.
“Sasaki Metrics for Analysis of Longitudinal Data on Manifolds,” In Proceedings of the 2012 IEEE conference on Computer Vision and Pattern Recognition (CVPR), pp. 1027--1034. 2012.
DOI: 10.1109/CVPR.2012.6247780
ABSTRACT
×
Longitudinal data arises in many applications in which the goal is to understand changes in individual entities over time. In this paper, we present a method for analyzing longitudinal data that take values in a Riemannian manifold. A driving application is to characterize anatomical shape changes and to distinguish between trends in anatomy that are healthy versus those that are due to disease. We present a generative hierarchical model in which each individual is modeled by a geodesic trend, which in turn is considered as a perturbation of the mean geodesic trend for the population. Each geodesic in the model can be uniquely parameterized by a starting point and velocity, i.e., a point in the tangent bundle. Comparison between these parameters is achieved through the Sasaki metric, which provides a natural distance metric on the tangent bundle. We develop a statistical hypothesis test for differences between two groups of longitudinal data by generalizing the Hotelling T2 statistic to manifolds. We demonstrate the ability of these methods to distinguish differences in shape changes in a comparison of longitudinal corpus callosum data in subjects with dementia versus healthily aging controls.
Stochastic Collocation Methods on Unstructured Grids in High Dimensions via Interpolation
A. Narayan, D. Xiu.
“Stochastic Collocation Methods on Unstructured Grids in High Dimensions via Interpolation,” In SIAM Journal on Scientific Computing, Vol. 34, No. 3, pp. A1729–-A1752. 2012.
DOI: 10.1137/110854059
ABSTRACT
×
In this paper we propose a method for conducting stochastic collocation on arbitrary sets of nodes. To accomplish this, we present the framework of least orthogonal interpolation, which allows one to construct interpolation polynomials based on arbitrarily located grids in arbitrary dimensions. These interpolation polynomials are constructed as a subspace of the family of orthogonal polynomials corresponding to the probability distribution function on stochastic space. This feature enables one to conduct stochastic collocation simulations in practical problems where one cannot adopt some popular node selections such as sparse grids or cubature nodes. We present in detail both the mathematical properties of the least orthogonal interpolation and its practical implementation algorithm. Numerical benchmark problems are also presented to demonstrate the efficacy of the method.
A. Narayan, Y. Marzouk, D. Xiu.
“Sequential Data Assimilation with Multiple Models,” In Journal of Computational Physics, Vol. 231, No. 19, pp. 6401--6418. 2012.
DOI: 10.1016/j.jcp.2012.06.002
ABSTRACT
Data assimilation is an essential tool for predicting the behavior of real physical systems given approximate simulation models and limited observations. For many complex systems, there may exist several models, each with different properties and predictive capabilities. It is desirable to incorporate multiple models into the assimilation procedure in order to obtain a more accurate prediction of the physics than any model alone can provide. In this paper, we propose a framework for conducting sequential data assimilation with multiple models and sources of data. The assimilated solution is a linear combination of all model predictions and data. One notable feature is that the combination takes the most general form with matrix weights. By doing so the method can readily utilize different weights in different sections of the solution state vectors, allow the models and data to have different dimensions, and deal with the case of a singular state covariance. We prove that the proposed assimilation method, termed direct assimilation, minimizes a variational functional, a generalized version of the one used in the classical Kalman filter. We also propose an efficient iterative assimilation method that assimilates two models at a time until all models and data are assimilated. The mathematical equivalence of the iterative method and the direct method is established. Numerical examples are presented to demonstrate the effectiveness of the new method.
Keywords: Uncertainty quantification, Data assimilation, Kalman filter, Model averaging
ElVis: A System for the Accurate and Interactive Visualization of High-Order Finite Element Solutions
B. Nelson, E. Liu, R.M. Kirby, R. Haimes.
“ElVis: A System for the Accurate and Interactive Visualization of High-Order Finite Element Solutions,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. 18, No. 12, pp. 2325--2334. Dec, 2012.
DOI: 10.1109/TVCG.2012.218
ABSTRACT
×
This paper presents the Element Visualizer (ElVis), a new, open-source scientific visualization system for use with high-order finite element solutions to PDEs in three dimensions. This system is designed to minimize visualization errors of these types of fields by querying the underlying finite element basis functions (e.g., high-order polynomials) directly, leading to pixel-exact representations of solutions and geometry. The system interacts with simulation data through runtime plugins, which only require users to implement a handful of operations fundamental to finite element solvers. The data in turn can be visualized through the use of cut surfaces, contours, isosurfaces, and volume rendering. These visualization algorithms are implemented using NVIDIA's OptiX GPU-based ray-tracing engine, which provides accelerated ray traversal of the high-order geometry, and CUDA, which allows for effective parallel evaluation of the visualization algorithms. The direct interface between ElVis and the underlying data differentiates it from existing visualization tools. Current tools assume the underlying data is composed of linear primitives; high-order data must be interpolated with linear functions as a result. In this work, examples drawn from aerodynamic simulations-high-order discontinuous Galerkin finite element solutions of aerodynamic flows in particular-will demonstrate the superiority of ElVis' pixel-exact approach when compared with traditional linear-interpolation methods. Such methods can introduce a number of inaccuracies in the resulting visualization, making it unclear if visual artifacts are genuine to the solution data or if these artifacts are the result of interpolation errors. Linear methods additionally cannot properly visualize curved geometries (elements or boundaries) which can greatly inhibit developers' debugging efforts. As we will show, pixel-exact visualization exhibits none of these issues, removing the visualization scheme as a source of - ncertainty for engineers using ElVis.
Fingerprint Image Segmentation using Data Manifold Characteristic Features
A.R.C. Paiva, T. Tasdizen.
“Fingerprint Image Segmentation using Data Manifold Characteristic Features,” In International Journal of Pattern Recognition and Artificial Intelligence, Vol. 26, No. 4, pp. (23 pages). 2012.
DOI: 10.1142/S0218001412560101
ABSTRACT
×
Automatic fingerprint identification systems (AFIS) have been studied extensively and are widely used for biometric identification. Given its importance, many well-engineered methods have been developed for the different stages that encompass those systems. The first stage of any such system is the segmentation of the actual fingerprint region from the background. This is typically achieved by classifying pixels, or blocks of pixels, based on a set of features. In this paper, we describe novel features for fingerprint segmentation that express the underlying manifold topology associated with image patches in a local neighborhood. It is shown that fingerprint patches seen in a high-dimensional space form a simple and highly regular circular manifold. The characterization of the manifold topology suggests a set of optimal features that characterize the local properties of the fingerprint. Thus, fingerprint segmentation can be formulated as a classification problem based on the deviation from the expected topology. This leads to features that are more robust to changes in contrast than mean, variance and coherence. The superior performance of the proposed features for fingerprint segmentation is shown in the eight datasets from the 2002 and 2004 Fingerprint Verification Competitions.
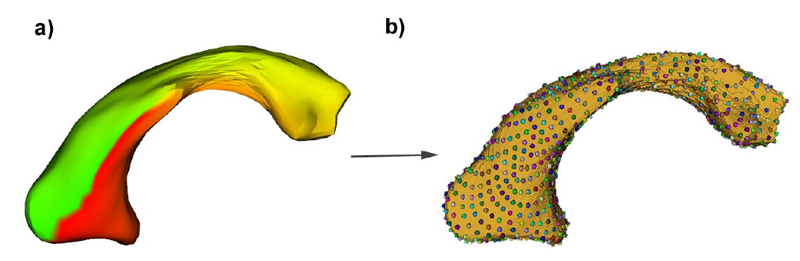
Combined {SPHARM-PDM} and entropy-based particle systems shape analysis framework
B. Paniagua, L. Bompard, J. Cates, R.T. Whitaker, M. Datar, C. Vachet, M. Styner.
“Combined SPHARM-PDM and entropy-based particle systems shape analysis framework,” In Medical Imaging 2012: Biomedical Applications in Molecular, Structural, and Functional Imaging, SPIE Intl Soc Optical Eng, March, 2012.
DOI: 10.1117/12.911228
PubMed ID: 24027625
PubMed Central ID: PMC3766973
ABSTRACT
×
Description of purpose: The NA-MIC SPHARM-PDM Toolbox represents an automated set of tools for the computation of 3D structural statistical shape analysis. SPHARM-PDM solves the correspondence problem by defining a first order ellipsoid aligned, uniform spherical parameterization for each object with correspondence established at equivalently parameterized points. However, SPHARM correspondence has shown to be inadequate for some biological shapes that are not well described by a uniform spherical parameterization. Entropy-based particle systems compute correspondence by representing surfaces as discrete point sets that does not rely on any inherent parameterization. However, they are sensitive to initialization and have little ability to recover from initial errors. By combining both methodologies we compute reliable correspondences in topologically challenging biological shapes. Data: Diverse subcortical structures cohorts were used, obtained from MR brain images. Method(s): The SPHARM-PDM shape analysis toolbox was used to compute point based correspondent models that were then used as initializing particles for the entropy-based particle systems. The combined framework was implemented as a stand-alone Slicer3 module, which works as an end-to-end shape analysis module. Results: The combined SPHARM-PDM-Particle framework has demonstrated to improve correspondence in the example dataset over the conventional SPHARM-PDM toolbox. Conclusions: The work presented in this paper demonstrates a two-sided improvement for the scientific community, being able to 1) find good correspondences among spherically topological shapes, that can be used in many morphometry studies 2) offer an end-to-end solution that will facilitate the access to shape analysis framework to users without computer expertise.
enRoute: Dynamic Path Extraction from Biological Pathway Maps for In-Depth Experimental Data Analysis
C Partl, A Lex, M Streit, D Kalkofen, K Kashofer, D Schmalstieg.
“enRoute: Dynamic Path Extraction from Biological Pathway Maps for In-Depth Experimental Data Analysis,” In Proceedings of the IEEE Symposium on Biological Data Visualization (BioVis '12), IEEE, pp. 107--114. 2012.
DOI: 10.1109/BioVis.2012.6378600
ABSTRACT
Pathway maps are an important source of information when analyzing functional implications of experimental data on biological processes. However, associating large quantities of data with nodes on a pathway map and allowing in depth-analysis at the same time is a challenging task. While a wide variety of approaches for doing so exist, they either do not scale beyond a few experiments or fail to represent the pathway appropriately. To remedy this, we introduce enRoute, a new approach for interactively exploring experimental data along paths that are dynamically extracted from pathways. By showing an extracted path side-by-side with experimental data, enRoute can present large amounts of data for every pathway node. It can visualize hundreds of samples, dozens of experimental conditions, and even multiple datasets capturing different aspects of a node at the same time. Another important property of this approach is its conceptual compatibility with arbitrary forms of pathways. Most notably, enRoute works well with pathways that are manually created, as they are available in large, public pathway databases. We demonstrate enRoute with pathways from the well-established KEGG database and expression as well as copy number datasets from humans and mice with more than 1,000 experiments. We validate enRoute using case studies with domain experts, who used enRoute to explore data for glioblastoma multiforme in humans and a model of steatohepatitis in mice.
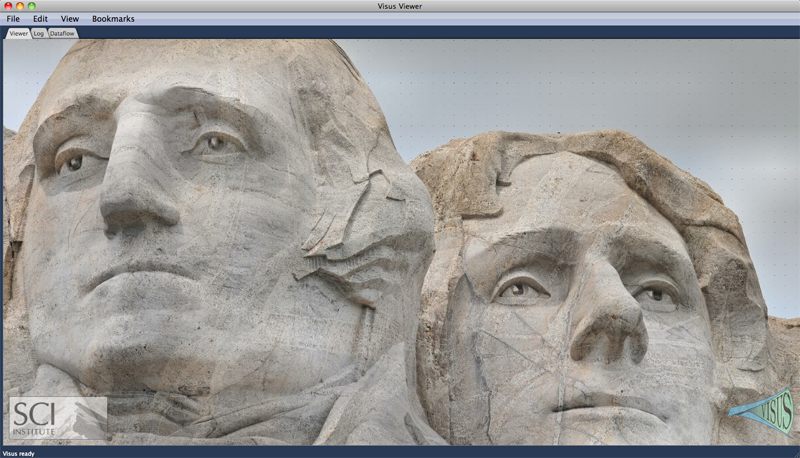
The {ViSUS} Visualization Framework
V. Pascucci, G. Scorzelli, B. Summa, P.-T. Bremer, A. Gyulassy, C. Christensen, S. Philip, S. Kumar.
“The ViSUS Visualization Framework,” In High Performance Visualization: Enabling Extreme-Scale Scientific Insight, Chapman and Hall/CRC Computational Science, Ch. 19, Edited by E. Wes Bethel and Hank Childs (LBNL) and Charles Hansen (UofU), Chapman and Hall/CRC, 2012.
ABSTRACT
×
The ViSUS software framework was designed with the primary philosophy that the visualization of massive data need not be tied to specialized hardware or infrastructure. In other words, a visualization environment for large data can be designed to be lightweight, highly scalable and run on a variety of plat- forms or hardware. Moreover, if designed generally such an infrastructure can have a wide variety of applications, all from the same code base. Figure 19.1 details example applications and the major components of the ViSUS infrastructure. The components can be grouped into three major categories. First, a lightweight and fast out-of-core data management framework using multi- resolution space filling curves. This allows the organization of information in an order that exploits the cache hierarchies of any modern data storage architectures. Second, a data flow framework that allows data to be processed during movement. Processing massive datasets in their entirety would be a long and expensive operation which hinders interactive exploration. By designing new algorithms to fit within this framework, data can be processed as it moves. Third, a portable visualization layer which was designed to scale from mobile devices to powerwall displays with same code base. In this chapter we will describe the ViSUS infrastructure, as well as give practical examples of its use in real world applications.
Mesh-Driven Vector Field Clustering and Visualization: An Image-Based Approach
Z. Peng, E. Grundy, R.S. Laramee, G. Chen, N. Croft.
“Mesh-Driven Vector Field Clustering and Visualization: An Image-Based Approach,” In IEEE Transactions on Visualization and Computer Graphics, 2011, Vol. 18, No. 2, pp. 283--298. February, 2012.
DOI: 10.1109/TVCG.2011.25
ABSTRACT
Vector field visualization techniques have evolved very rapidly over the last two decades, however, visualizing vector fields on complex boundary surfaces from computational flow dynamics (CFD) still remains a challenging task. In part, this is due to the large, unstructured, adaptive resolution characteristics of the meshes used in the modeling and simulation process. Out of the wide variety of existing flow field visualization techniques, vector field clustering algorithms offer the advantage of capturing a detailed picture of important areas of the domain while presenting a simplified view of areas of less importance. This paper presents a novel, robust, automatic vector field clustering algorithm that produces intuitive and insightful images of vector fields on large, unstructured, adaptive resolution boundary meshes from CFD. Our bottom-up, hierarchical approach is the first to combine the properties of the underlying vector field and mesh into a unified error-driven representation. The motivation behind the approach is the fact that CFD engineers may increase the resolution of model meshes according to importance. The algorithm has several advantages. Clusters are generated automatically, no surface parameterization is required, and large meshes are processed efficiently. The most suggestive and important information contained in the meshes and vector fields is preserved while less important areas are simplified in the visualization. Users can interactively control the level of detail by adjusting a range of clustering distance measure parameters. We describe two data structures to accelerate the clustering process. We also introduce novel visualizations of clusters inspired by statistical methods. We apply our method to a series of synthetic and complex, real-world CFD meshes to demonstrate the clustering algorithm results.
Keywords: Vector Field Visualization, Clustering, Feature-based, Surfaces
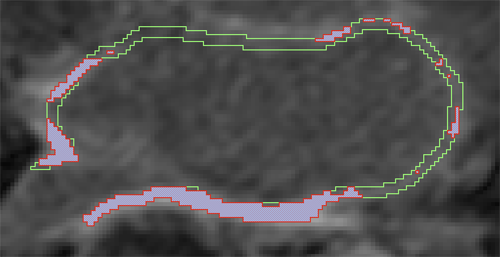
Automatic classification of scar tissue in late gadolinium enhancement cardiac MRI for the assessment of left-atrial wall injury after radiofrequency ablation
D. Perry, A. Morris, N. Burgon, C. McGann, R.S. MacLeod, J. Cates.
“Automatic classification of scar tissue in late gadolinium enhancement cardiac MRI for the assessment of left-atrial wall injury after radiofrequency ablation,” In SPIE Proceedings, Vol. 8315, pp. (published online). 2012.
DOI: 10.1117/12.910833
PubMed ID: 24236224
PubMed Central ID: PMC3824273
ABSTRACT
×
Radiofrequency ablation is a promising procedure for treating atrial fibrillation (AF) that relies on accurate lesion delivery in the left atrial (LA) wall for success. Late Gadolinium Enhancement MRI (LGE MRI) at three months post-ablation has proven effective for noninvasive assessment of the location and extent of scar formation, which are important factors for predicting patient outcome and planning of redo ablation procedures. We have developed an algorithm for automatic classification in LGE MRI of scar tissue in the LA wall and have evaluated accuracy and consistency compared to manual scar classifications by expert observers. Our approach clusters voxels based on normalized intensity and was chosen through a systematic comparison of the performance of multivariate clustering on many combinations of image texture. Algorithm performance was determined by overlap with ground truth, using multiple overlap measures, and the accuracy of the estimation of the total amount of scar in the LA. Ground truth was determined using the STAPLE algorithm, which produces a probabilistic estimate of the true scar classification from multiple expert manual segmentations. Evaluation of the ground truth data set was based on both inter- and intra-observer agreement, with variation among expert classifiers indicating the difficulty of scar classification for a given a dataset. Our proposed automatic scar classification algorithm performs well for both scar localization and estimation of scar volume: for ground truth datasets considered easy, variability from the ground truth was low; for those considered difficult, variability from ground truth was on par with the variability across experts.
Multiscale Modeling of High Explosives for Transportation Accidents
J.R. Peterson, J.C. Beckvermit, T. Harman, M. Berzins, C.A. Wight.
“Multiscale Modeling of High Explosives for Transportation Accidents,” In Proceedings of the 1st Conference of the Extreme Science and Engineering Discovery Environment: Bridging from the eXtreme to the campus and beyond, 2012.
DOI: 10.1145/2335755.2335828
ABSTRACT
×
The development of a reaction model to simulate the accidental detonation of a large array of seismic boosters in a semi-truck subject to fire is considered. To test this model large scale simulations of explosions and detonations were performed by leveraging the massively parallel capabilities of the Uintah Computational Framework and the XSEDE computational resources. Computed stress profiles in bulk-scale explosive materials were validated using compaction simulations of hundred micron scale particles and found to compare favorably with experimental data. A validation study of reaction models for deflagration and detonation showed that computational grid cell sizes up to 10 mm could be used without loss of fidelity. The Uintah Computational Framework shows linear scaling up to 180K cores which combined with coarse resolution and validated models will now enable simulations of semi-truck scale transportation accidents for the first time.
An Eulerian-Lagrangian Computational Model for Deagration and Detonation of High Explosives
J. Peterson, C. Wight.
“An Eulerian-Lagrangian Computational Model for Deagration and Detonation of High Explosives,” In Combustion and Flame, Vol. 159, No. 7, pp. 2491--2499. 2012.
DOI: 10.1016/j.combustflame.2012.02.006
ABSTRACT
A solid phase explosives deflagration and detonation model capable of surface burning, convective bulk burning and detonation is formulated in the context of Eulerian–Lagrangian material mechanics. Well-validated combustion and detonation models, WSB and JWL++, are combined with two simple, experimentally indicated transition thresholds partitioning the three reaction regimes. Standard experiments are simulated, including the Aluminum Flyer Plate test, the Cylinder test, the rate stick test and the Steven test in order to validate the model. Cell and particle resolution dependence of simulation metrics are presented and global uncertainties assigned. Error quantification comparisons with experiments led to values generally below 7% (1σ). Finally, gas flow through porous media is implicated as the driving force behind the deflagration to detonation transition.
A Higher-Order Generalized Singular Value Decomposition for Comparison of Global mRNA Expression from Multiple Organisms
S.P. Ponnapalli, M.A. Saunders, C.F. Van Loan, O. Alter.
“A Higher-Order Generalized Singular Value Decomposition for Comparison of Global mRNA Expression from Multiple Organisms,” In PLoS One, Vol. 6, No. 12, pp. e28072. 2012.
DOI: 10.1371/journal.pone.0028072
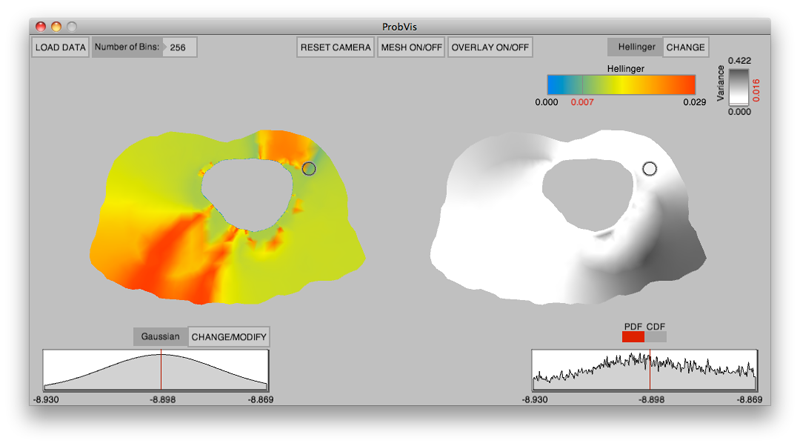
Interactive visualization of probability and cumulative density functions
K. Potter, R.M. Kirby, D. Xiu, C.R. Johnson.
“Interactive visualization of probability and cumulative density functions,” In International Journal of Uncertainty Quantification, Vol. 2, No. 4, pp. 397--412. 2012.
DOI: 10.1615/Int.J.UncertaintyQuantification.2012004074
PubMed ID: 23543120
PubMed Central ID: PMC3609671
ABSTRACT
×
The probability density function (PDF), and its corresponding cumulative density function (CDF), provide direct statistical insight into the characterization of a random process or field. Typically displayed as a histogram, one can infer probabilities of the occurrence of particular events. When examining a field over some two-dimensional domain in which at each point a PDF of the function values is available, it is challenging to assess the global (stochastic) features present within the field. In this paper, we present a visualization system that allows the user to examine two-dimensional data sets in which PDF (or CDF) information is available at any position within the domain. The tool provides a contour display showing the normed difference between the PDFs and an ansatz PDF selected by the user, and furthermore allows the user to interactively examine the PDF at any particular position. Canonical examples of the tool are provided to help guide the reader into the mapping of stochastic information to visual cues along with a description of the use of the tool for examining data generated from a uncertainty quantification exercise accomplished within the field of electrophysiology.
Keywords: visualization, probability density function, cumulative density function, generalized polynomial chaos, stochastic Galerkin methods, stochastic collocation methods
From Quantification to Visualization: A Taxonomy of Uncertainty Visualization Approaches
K. Potter, P. Rosen, C.R. Johnson.
“From Quantification to Visualization: A Taxonomy of Uncertainty Visualization Approaches,” In Uncertainty Quantification in Scientific Computing, IFIP Advances in Information and Communication Technology Series, Vol. 377, Edited by Andrew Dienstfrey and Ronald Boisvert, Springer, pp. 226--249. 2012.
DOI: 10.1007/978-3-642-32677-6_15
ABSTRACT
×
Quantifying uncertainty is an increasingly important topic across many domains. The uncertainties present in data come with many diverse representations having originated from a wide variety of domains. Communicating these uncertainties is a task often left to visualization without clear connection between the quantification and visualization. In this paper, we first identify frequently occurring types of uncertainty. Second, we connect those uncertainty representations to ones commonly used in visualization. We then look at various approaches to visualizing this uncertainty by partitioning the work based on the dimensionality of the data and the dimensionality of the uncertainty. We also discuss noteworthy exceptions to our taxonomy along with future research directions for the uncertainty visualization community.
Keywords: scidac, netl, uncertainty visualization
Building Spatiotemporal Anatomical Models using Joint {4-D} Segmentation, Registration, and Subject-Speci fic Atlas Estimation
M.W. Prastawa, S.P. Awate, G. Gerig.
“Building Spatiotemporal Anatomical Models using Joint 4-D Segmentation, Registration, and Subject-Speci fic Atlas Estimation,” In Proceedings of the 2012 IEEE Mathematical Methods in Biomedical Image Analysis (MMBIA) Conference, pp. 49--56. 2012.
DOI: 10.1109/MMBIA.2012.6164740
PubMed ID: 23568185
PubMed Central ID: PMC3615562
ABSTRACT
×
Longitudinal analysis of anatomical changes is a vital component in many personalized-medicine applications for predicting disease onset, determining growth/atrophy patterns, evaluating disease progression, and monitoring recovery. Estimating anatomical changes in longitudinal studies, especially through magnetic resonance (MR) images, is challenging because of temporal variability in shape (e.g. from growth/atrophy) and appearance (e.g. due to imaging parameters and tissue properties affecting intensity contrast, or from scanner calibration). This paper proposes a novel mathematical framework for constructing subject-specific longitudinal anatomical models. The proposed method solves a generalized problem of joint segmentation, registration, and subject-specific atlas building, which involves not just two images, but an entire longitudinal image sequence. The proposed framework describes a novel approach that integrates fundamental principles that underpin methods for image segmentation, image registration, and atlas construction. This paper presents evaluation on simulated longitudinal data and on clinical longitudinal brain MRI data. The results demonstrate that the proposed framework effectively integrates information from 4-D spatiotemporal data to generate spatiotemporal models that allow analysis of anatomical changes over time.
Keywords: namic, adni, autism
Generalised Polynomial Chaos for a Class of Linear Conservation Laws
R. Pulch, D. Xiu.
“Generalised Polynomial Chaos for a Class of Linear Conservation Laws,” In Journal of Scientific Computing, Vol. 51, No. 2, pp. 293--312. 2012.
DOI: 10.1007/s10915-011-9511-5
ABSTRACT
×
Mathematical modelling of dynamical systems often yields partial differential equations (PDEs) in time and space, which represent a conservation law possibly including a source term. Uncertainties in physical parameters can be described by random variables. To resolve the stochastic model, the Galerkin technique of the generalised polynomial chaos results in a larger coupled system of PDEs. We consider a certain class of linear systems of conservation laws, which exhibit a hyperbolic structure. Accordingly, we analyse the hyperbolicity of the corresponding coupled system of linear conservation laws from the polynomial chaos. Numerical results of two illustrative examples are presented.
Keywords: Generalised polynomial chaos, Galerkin method, Random parameter, Conservation laws, Hyperbolic systems
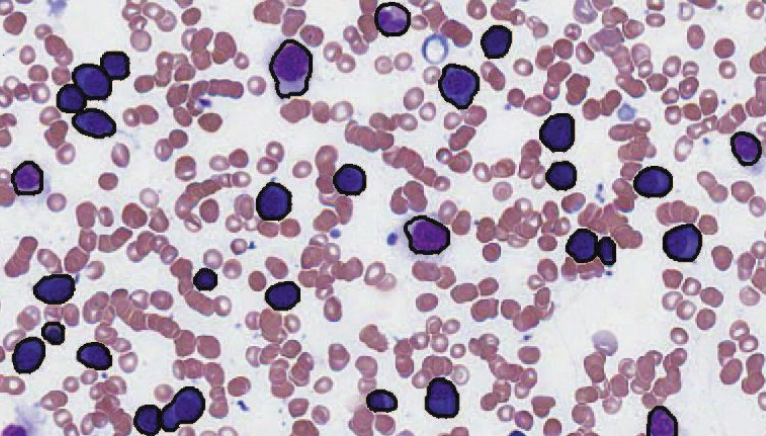
Segmentation and Two-Step Classification of White Blood Cells in Peripheral Blood Smear
N. Ramesh, B. J. Dangott, M. Salama, T. Tasdizen.
“Segmentation and Two-Step Classification of White Blood Cells in Peripheral Blood Smear,” In Journal of Pathology Informatics, Vol. 3, No. 13, 2012.
ABSTRACT
An automated system for differential white blood cell (WBC) counting based on morphology can make manual differential leukocyte counts faster and less tedious for pathologists and laboratory professionals. We present an automated system for isolation and classification of WBCs in manually prepared, Wright stained, peripheral blood smears from whole slide images (WSI). Methods: A simple, classification scheme using color information and morphology is proposed. The performance of the algorithm was evaluated by comparing our proposed method with a hematopathologist's visual classification. The isolation algorithm was applied to 1938 subimages of WBCs, 1804 of them were accurately isolated. Then, as the first step of a two-step classification process, WBCs were broadly classified into cells with segmented nuclei and cells with nonsegmented nuclei. The nucleus shape is one of the key factors in deciding how to classify WBCs. Ambiguities associated with connected nuclear lobes are resolved by detecting maximum curvature points and partitioning them using geometric rules. The second step is to define a set of features using the information from the cytoplasm and nuclear regions to classify WBCs using linear discriminant analysis. This two-step classification approach stratifies normal WBC types accurately from a whole slide image. Results: System evaluation is performed using a 10-fold cross-validation technique. Confusion matrix of the classifier is presented to evaluate the accuracy for each type of WBC detection. Experiments show that the two-step classification implemented achieves a 93.9\% overall accuracy in the five subtype classification. Conclusion: Our methodology achieves a semiautomated system for the detection and classification of normal WBCs from scanned WSI. Further studies will be focused on detecting and segmenting abnormal WBCs, comparison of 20x and 40x data, and expanding the applications for bone marrow aspirates.
Segmentation of Haematopoeitic Cells in Bone Marrow Using Circle Detection and Splitting Techniques
N. Ramesh, M.E. Salama, T. Tasdizen.
“Segmentation of Haematopoeitic Cells in Bone Marrow Using Circle Detection and Splitting Techniques,” In 9th IEEE International Symposium on Biomedical Imaging (ISBI), pp. 206--209. 2012.
DOI: 10.1109/ISBI.2012.6235520
ABSTRACT
×
Bone marrow evaluation is indicated when peripheral blood abnormalities are not explained by clinical, physical, or laboratory findings. In this paper, we propose a novel method for segmentation of haematopoietic cells in the bone marrow from scanned slide images. Segmentation of clumped cells is a challenging problem for this application. We first use color information and morphology to eliminate red blood cells and the background. Clumped haematopoietic cells are then segmented using circle detection and a splitting algorithm based on the detected circle centers. The Hough Transform is used for circle detection and to find the number and positions of circle centers in each region. The splitting algorithm is based on detecting the maximum curvature points, and partitioning them based on information obtained from the centers of the circles in each region. The performance of the segmentation algorithm for haematopoietic cells is evaluated by comparing our proposed method with a hematologist's visual segmentation in a set of 3748 cells.