
SCI Publications
2011
![]()
W. Liu, S. Awate, J. Anderson, D. Yurgelun-Todd, P.T. Fletcher.
“Monte Carlo expectation maximization with hidden Markov models to detect functional networks in resting-state fMRI,” In Machine Learning in Medical Imaging, Lecture Notes in Computer Science (LNCS), Vol. 7009/2011, pp. 59--66. 2011.
DOI: 10.1007/978-3-642-24319-6_8
![]()
J. Luitjens, M. Berzins.
“Scalable parallel regridding algorithms for block-structured adaptive mesh renement,” In Concurrency And Computation: Practice And Experience, Vol. 23, No. 13, John Wiley & Sons, Ltd., pp. 1522--1537. 2011.
ISSN: 1532--0634
DOI: 10.1002/cpe.1719
![]()
J.P. Luitjens.
“The Scalability of Parallel Adaptive Mesh Refinement Within Uintah,” Note: Advisor: Martin Berzins, School of Computing, University of Utah, 2011.
Solutions to Partial Differential Equations (PDEs) are often computed by discretizing the domain into a collection of computational elements referred to as a mesh. This solution is an approximation with an error that decreases as the mesh spacing decreases. However, decreasing the mesh spacing also increases the computational requirements. Adaptive mesh refinement (AMR) attempts to reduce the error while limiting the increase in computational requirements by refining the mesh locally in regions of the domain that have large error while maintaining a coarse mesh in other portions of the domain. This approach often provides a solution that is as accurate as that obtained from a much larger fixed mesh simulation, thus saving on both computational time and memory. However, historically, these AMR operations often limit the overall scalability of the application.
Adapting the mesh at runtime necessitates scalable regridding and load balancing algorithms. This dissertation analyzes the performance bottlenecks for a widely used regridding algorithm and presents two new algorithms which exhibit ideal scalability. In addition, a scalable space-filling curve generation algorithm for dynamic load balancing is also presented. The performance of these algorithms is analyzed by determining their theoretical complexity, deriving performance models, and comparing the observed performance to those performance models. The models are then used to predict performance on larger numbers of processors. This analysis demonstrates the necessity of these algorithms at larger numbers of processors. This dissertation also investigates methods to more accurately predict workloads based on measurements taken at runtime. While the methods used are not new, the application of these methods to the load balancing process is. These methods are shown to be highly accurate and able to predict the workload within 3% error. By improving the accuracy of these estimations, the load imbalance of the simulation can be reduced, thereby increasing the overall performance.
![]()
J. Luitjens, M. Berzins.
“Scalable parallel regridding algorithms for block-structured adaptive mesh refinement,” In Concurrency and Computation: Practice and Experience, Vol. 23, No. 13, pp. 1522--1537. September, 2011.
DOI: 10.1002/cpe.1719
Block-structured adaptive mesh refinement (BSAMR) is widely used within simulation software because it improves the utilization of computing resources by refining the mesh only where necessary. For BSAMR to scale onto existing petascale and eventually exascale computers all portions of the simulation need to weak scale ideally. Any portions of the simulation that do not will become a bottleneck at larger numbers of cores. The challenge is to design algorithms that will make it possible to avoid these bottlenecks on exascale computers. One step of existing BSAMR algorithms involves determining where to create new patches of refinement. The Berger–Rigoutsos algorithm is commonly used to perform this task. This paper provides a detailed analysis of the performance of two existing parallel implementations of the Berger– Rigoutsos algorithm and develops a new parallel implementation of the Berger–Rigoutsos algorithm and a tiled algorithm that exhibits ideal scalability. The analysis and computational results up to 98 304 cores are used to design performance models which are then used to predict how these algorithms will perform on 100 M cores.
![]()
S.A. Maas, B.J. Ellis, D.S. Rawlins, L.T. Edgar, C.R. Henak, J.A. Weiss.
“Implementation and Verification of a Nodally-Integrated Tetrahedral Element in FEBio,” SCI Technical Report, No. UUSCI-2011-007, SCI Institute, University of Utah, 2011.
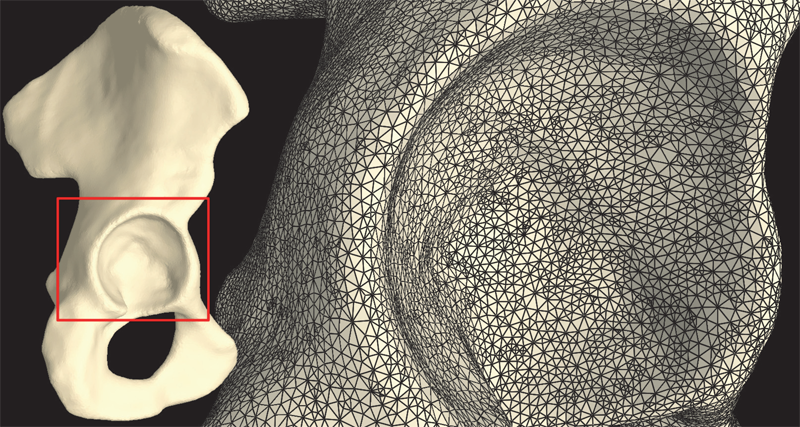
Keywords: MRL
![]()
R.S. MacLeod, J.J.E. Blauer.
“Atrial Fibrillation,” In Multimodal Cardiovascular Imaging: Principles and Clinical Applications, Ch. 25, Edited by O. Pahlm and G. Wagner, McGraw Hill, 2011.
ISBN: 0071613463
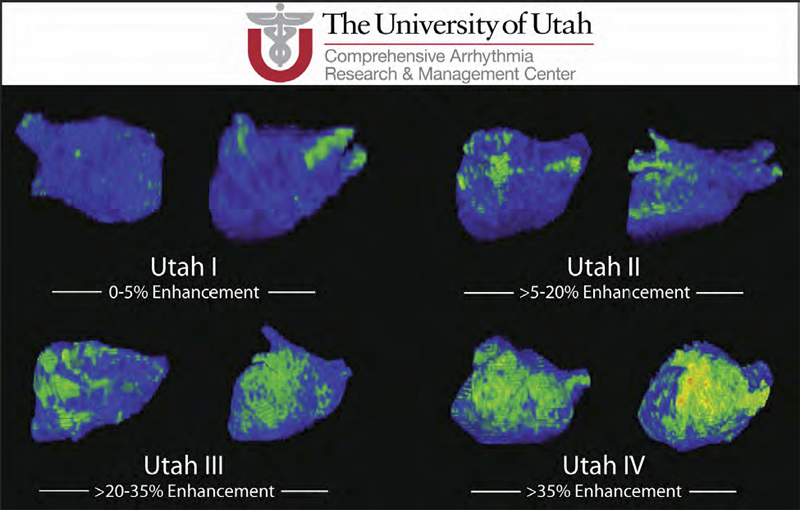
Atrial fibrillation (AF) is the most common form of cardiac arrhythmia so that a review of the role imaging in AF is a natural topic to include in this book. Further motivation comes from the fact that the treatment of AF probably includes more different forms of imaging, often merged or combined in a variety of ways, than perhaps any other clinical intervention. A typical clinical electrophysiology lab for the treatment of AF usually contains no less than 6 and often more than 8 individual monitors, each rendering some form of image based information about the patient undergoing therapy. There is naturally great motivation to merge different images and different imaging modalities in the setting of AF but also very challenging because of a host of factors related to the small size, extremely thin walls, the large natural variation in atrial shape, and the fact that fibrillation is occurring so that atrial shape is changing rapidly and irregularly. Thus, the use of multimodal imaging has recently become a very active and challenging area of image processing and analysis research and development, driven by an enormous clinical need to understand and treat a disease that affects some 5 million Americans alone, a number that is predicted to increase to almost 16 million by 2050.
In this chapter we attempt to provide an overview of the large variety of imaging modalities and uses in the management and understanding of atrial fibrillation, with special emphasis on the most novel applications of magnetic resonance imaging (MRI) technology. To provide clinical and biomedical motivation, we outline the basics of the disease together with some contemporary hypotheses about its etiology and management. We then describe briefly the imaging modalities in common use in the management and research of AF, then focus on the use or MRI for all phases of the management of patients with AF and indicate some of the major engineering challenges that can motivate further progress.
Keywords: ablation, carma, cvrti, 5P41-RR012553-10
![]()
J. Mandel, J.D. Beezley, A. Kochanski, V.Y. Kondratenko, L. Zhang, E. Anderson, J. Daniels II, C.T. Silva, C.R. Johnson.
“A wildland fire modeling and visualization environment,” In Proceedings of the Ninth Symposium on Fire and Forest Meteorology, pp. (published online). 2011.
![]()
T. Martin, E. Cohen, R.M. Kirby.
“Direct Isosurface Visualization of Hex-Based High-Order Geometry and Attribute Representations,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. PP, No. 99, pp. 1--14. 2011.
ISSN: 1077-2626
DOI: 10.1109/TVCG.2011.103
In this paper, we present a novel isosurface visualization technique that guarantees the accuarate visualization of isosurfaces with complex attribute data defined on (un-)structured (curvi-)linear hexahedral grids. Isosurfaces of high-order hexahedralbased finite element solutions on both uniform grids (including MRI and CT scans) and more complex geometry represent a domain of interest that can be rendered using our algorithm. Additionally, our technique can be used to directly visualize solutions and attributes in isogeometric analysis, an area based on trivariate high-order NURBS (Non-Uniform Rational B-splines) geometry and attribute representations for the analysis. Furthermore, our technique can be used to visualize isosurfaces of algebraic functions. Our approach combines subdivision and numerical root-finding to form a robust and efficient isosurface visualization algorithm that does not miss surface features, while finding all intersections between a view frustum and desired isosurfaces. This allows the use of view-independent transparency in the rendering process. We demonstrate our technique through a straightforward CPU implementation on both complexstructured and complex-unstructured geometry with high-order simulation solutions, isosurfaces of medical data sets, and isosurfaces of algebraic functions.
![]()
C.J. McGann, E.G. Kholmovski, J.J. Blauer, S. Vijayakumar, T.S. Haslam, J.E. Cates, E.V. DiBella, N.S. Burgon, B. Wilson, A.J. Alexander, M.W. Prastawa, M. Daccarett, G. Vergara, N.W. Akoum, D.L. Parker, R.S. MacLeod, N.F. Marrouche.
“Dark Regions of No-Reflow on Late Gadolinium Enhancement Magnetic Resonance Imaging Result in Scar Formation After Atrial Fibrillation Ablation,” In Journal of the American College of Cardiology, Vol. 58, No. 2, pp. 177--185. 2011.
DOI: 10.1016/j.jacc.2011.04.008
PubMed ID: 21718914
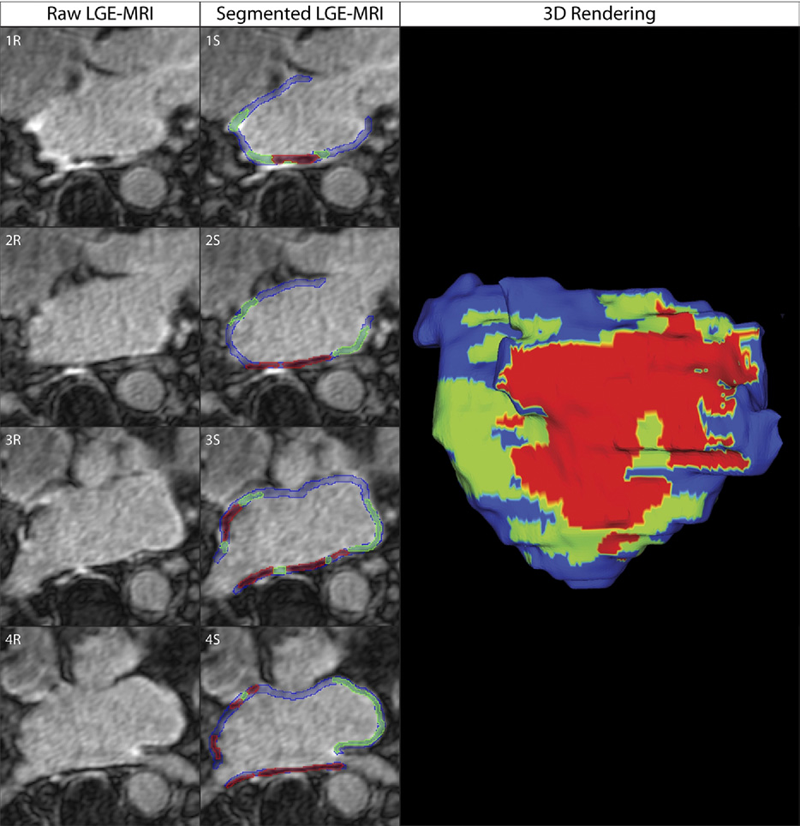
Objectives: The aim of this study was to assess acute ablation injuries seen on late gadolinium enhancement (LGE) magnetic resonance imaging (MRI) immediately post-ablation (IPA) and the association with permanent scar 3 months post-ablation (3moPA).
Background: Success rates for atrial fibrillation catheter ablation vary significantly, in part because of limited information about the location, extent, and permanence of ablation injury at the time of procedure. Although the amount of scar on LGE MRI months after ablation correlates with procedure outcomes, early imaging predictors of scar remain elusive.
Methods: Thirty-seven patients presenting for atrial fibrillation ablation underwent high-resolution MRI with a 3-dimensional LGE sequence before ablation, IPA, and 3moPA using a 3-T scanner. The acute left atrial wall injuries on IPA scans were categorized as hyperenhancing (HE) or nonenhancing (NE) and compared with scar 3moPA.
Results: Heterogeneous injuries with HE and NE regions were identified in all patients. Dark NE regions in the left atrial wall on LGE MRI demonstrate findings similar to the \"no-reflow\" phenomenon. Although the left atrial wall showed similar amounts of HE, NE, and normal tissue IPA (37.7 ± 13\%, 34.3 ± 14\%, and 28.0 ± 11\%, respectively; p = NS), registration of IPA injuries with 3moPA scarring demonstrated that 59.0 ± 19\% of scar resulted from NE tissue, 30.6 ± 15\% from HE tissue, and 10.4 ± 5\% from tissue identified as normal. Paired t-test comparisons were all statistically significant among NE, HE, and normal tissue types (p less than 0.001). Arrhythmia recurrence at 1-year follow-up correlated with the degree of wall enhancement 3moPA (p = 0.02).
Conclusion: Radiofrequency ablation results in heterogeneous injury on LGE MRI with both HE and NE wall lesions. The NE lesions demonstrate no-reflow characteristics and reveal a better predictor of final scar at 3 months. Scar correlates with procedure outcomes, further highlighting the importance of early scar prediction. (J Am Coll Cardiol 2011;58:177–85) © 2011 by the American College of Cardiology Foundation
![]()
Q. Meng, M. Berzins, J. Schmidt.
“Using Hybrid Parallelism to improve memory use in Uintah,” In Proceedings of the TeraGrid 2011 Conference, Salt Lake City, Utah, ACM, July, 2011.
DOI: 10.1145/2016741.2016767
The Uintah Software framework was developed to provide an environment for solving fluid-structure interaction problems on structured adaptive grids on large-scale, long-running, data-intensive problems. Uintah uses a combination of fluid-flow solvers and particle-based methods for solids together with a novel asynchronous task-based approach with fully automated load balancing. Uintah's memory use associated with ghost cells and global meta-data has become a barrier to scalability beyond O(100K) cores. A hybrid memory approach that addresses this issue is described and evaluated. The new approach based on a combination of Pthreads and MPI is shown to greatly reduce memory usage as predicted by a simple theoretical model, with comparable CPU performance.
Keywords: Uintah, C-SAFE, parallel computing
![]()
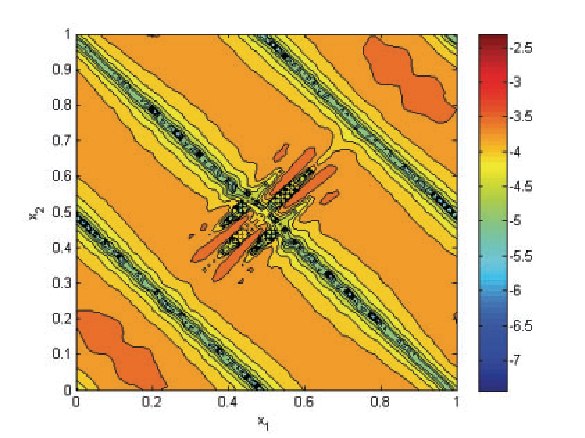
H. Mirzaee, Liangyue, J.K. Ryan, R.M. Kirby.
“Smoothness-Increasing Accuracy-Conserving (SIAC) Postprocessing for Discontinuous Galerkin Solutions Over Structured Triangular Meshes,” In SIAM Journal of Numerical Analysis, Vol. 49, No. 5, pp. 1899--1920. 2011.
![]()
H. Mirzaee, J.K. Ryan, R.M. Kirby.
“Efficient Implementation of Smoothness-Increasing Accuracy-Conserving (SIAC) Filters for Discontinuous Galerkin Solutions,” In Journal of Scientific Computing, pp. (in press). 2011.
DOI: 10.1007/s10915-011-9535-x
The discontinuous Galerkin (DG) methods provide a high-order extension of the finite volume method in much the same way as high-order or spectral/hp elements extend standard finite elements. However, lack of inter-element continuity is often contrary to the smoothness assumptions upon which many post-processing algorithms such as those used in visualization are based. Smoothness-increasing accuracy-conserving (SIAC) filters were proposed as a means of ameliorating the challenges introduced by the lack of regularity at element interfaces by eliminating the discontinuity between elements in a way that is consistent with the DG methodology; in particular, high-order accuracy is preserved and in many cases increased. The goal of this paper is to explicitly define the steps to efficient computation of this filtering technique as applied to both structured triangular and quadrilateral meshes. Furthermore, as the SIAC filter is a good candidate for parallelization, we provide, for the first time, results that confirm anticipated performance scaling when parallelized on a shared-memory multi-processor machine.
![]()
M.J. Mlodzianoski, J.M. Schreiner, S.P. Callahan, K. Smolková, A. Dlasková, J. Šantorová, P. Ježek, J. Bewersdorf.
“Sample drift correction in 3D fluorescence photoactivation localization microscopy,” In Optics Express, Vol. 19, No. 16, pp. 15009--15019. 2011.
DOI: 10.1364/OE.19.015009
![]()
![]()
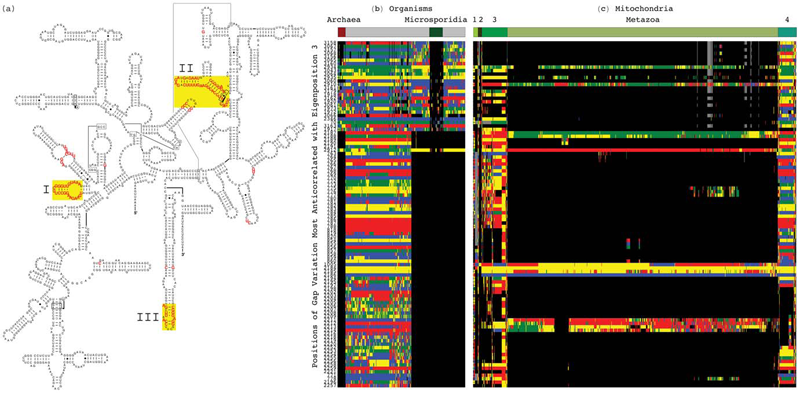
C. Muralidhara, A.M. Gross, R.R. Gutell, O. Alter.
“Tensor Decomposition Reveals Concurrent Evolutionary Convergences and Divergences and Correlations with Structural Motifs in Ribosomal RNA,” In PLoS ONE, Vol. 6, No. 4, Public Library of Science, pp. e18768. April, 2011.
DOI: 10.1371/journal.pone.0018768
![]()
A. Narayan, D. Xiu.
“Distributional Sensitivity for Uncertainty Quantification,” In Communications in Computational Physics, Vol. 10, No. 1, pp. 140--160. 2011.
DOI: 10.4208/cicp.160210.300710a
In this work we consider a general notion of distributional sensitivity, which measures the variation in solutions of a given physical/mathematical system with respect to the variation of probability distribution of the inputs. This is distinctively different from the classical sensitivity analysis, which studies the changes of solutions with respect to the values of the inputs. The general idea is measurement of sensitivity of outputs with respect to probability distributions, which is a well-studied concept in related disciplines. We adapt these ideas to present a quantitative framework in the context of uncertainty quantification for measuring such a kind of sensitivity and a set of efficient algorithms to approximate the distributional sensitivity numerically. A remarkable feature of the algorithms is that they do not incur additional computational effort in addition to a one-time stochastic solver. Therefore, an accurate stochastic computation with respect to a prior input distribution is needed only once, and the ensuing distributional sensitivity computation for different input distributions is a post-processing step. We prove that an accurate numericalmodel leads to accurate calculations of this sensitivity, which applies not just to slowly-converging Monte-Carlo estimates, but also to exponentially convergent spectral approximations. We provide computational examples to demonstrate the ease of applicability and verify the convergence claims.
Keywords: Uncertainty quantification, epistemic uncertainty, distributional sensitivity, generalized polynomial chaos
![]()
B. Nelson, R. Haimes, R.M. Kirby.
“GPU-Based Interactive Cut-Surface Extraction From High-0rder Finite Element Fields,” In IEEE Transactions on Visualization and Computer Graphics (IEEE Visualization Issue), Vol. 17, No. 12, pp. 1803--1811. 2011.
![]()
J.T. Oden, O. Ghattas, J.L. King, B.I. Schneider, K. Bartschat, F. Darema, J. Drake, T. Dunning, D. Estep, S. Glotzer, M. Gurnis, C.R. Johnson, D.S. Katz, D. Keyes, S. Kiesler, S. Kim, J. Kinter, G. Klimeck, C.W. McCurdy, R. Moser, C. Ott, A. Patra, L. Petzold, T. Schlick, K. Schulten, V. Stodden, J. Tromp, M. Wheeler, S.J. Winter, C. Wu, K. Yelick.
“Cyber Science and Engineering: A Report of the National Science Foundation Advisory Committee for Cyberinfrastructure Task Force on Grand Challenges,” Note: NSF Report, 2011.
This document contains the findings and recommendations of the NSF – Advisory Committee for Cyberinfrastructure Task Force on Grand Challenges addressed by advances in Cyber Science and Engineering. The term Cyber Science and Engineering (CS&E) is introduced to describe the intellectual discipline that brings together core areas of science and engineering, computer science, and computational and applied mathematics in a concerted effort to use the cyberinfrastructure (CI) for scientific discovery and engineering innovations; CS&E is computational and data-based science and engineering enabled by CI. The report examines a host of broad issues faced in addressing the Grand Challenges of science and technology and explores how those can be met by advances in CI. Included in the report are recommendations for new programs and initiatives that will expand the portfolio of the Office of Cyberinfrastructure and that will be critical to advances in all areas of science and engineering that rely on the CI.
![]()
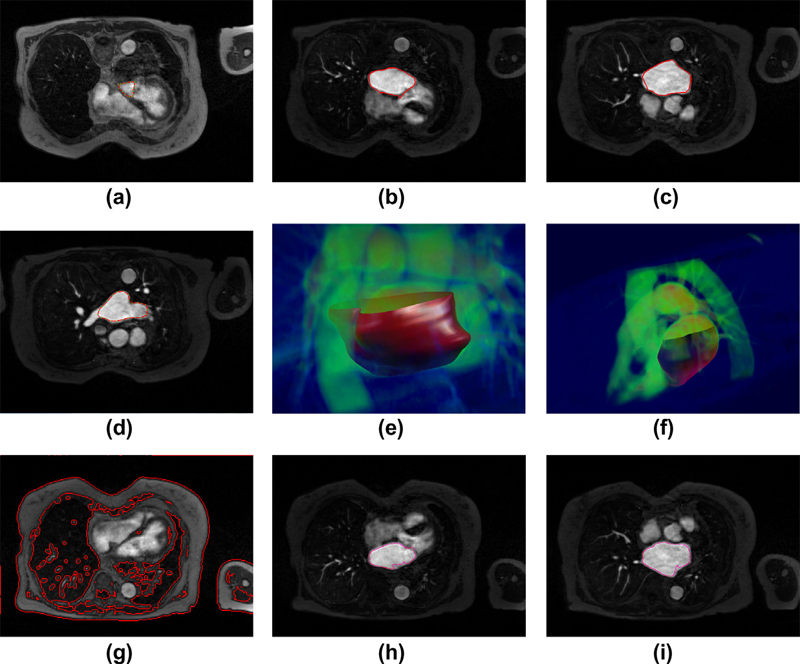
Y. Pan, W.-K. Jeong, R.T. Whitaker.
“Markov surfaces: A probabilistic framework for user-assisted three-dimensional image segmentation,” In Computer Vision and Image Understanding, Vol. 115, No. 10, pp. 1375--1383. 2011.
Valerio Pascucci, Xavier Tricoche, Hans Hagen, Julien Tierny.
“Topological Methods in Data Analysis and Visualization: Theory, Algorithms, and Applications (Mathematics and Visualization),” Springer, 2011.
ISBN: 978-3642150135
![]()
T. Peterka, R. Ross, A. Gyulassy, V. Pascucci, W. Kendall, H.-W. Shen, T.-Y. Lee, A. Chaudhuri.
“Scalable Parallel Building Blocks for Custom Data Analysis,” In Proceedings of the 2011 IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV), pp. 105--112. October, 2011.
DOI: 10.1109/LDAV.2011.6092324
We present a set of building blocks that provide scalable data movement capability to computational scientists and visualization researchers for writing their own parallel analysis. The set includes scalable tools for domain decomposition, process assignment, parallel I/O, global reduction, and local neighborhood communicationtasks that are common across many analysis applications. The global reduction is performed with a new algorithm, described in this paper, that efficiently merges blocks of analysis results into a smaller number of larger blocks. The merging is configurable in the number of blocks that are reduced in each round, the number of rounds, and the total number of resulting blocks. We highlight the use of our library in two analysis applications: parallel streamline generation and parallel Morse-Smale topological analysis. The first case uses an existing local neighborhood communication algorithm, whereas the latter uses the new merge algorithm.
Page 62 of 144